Introducing Learning Agents: Continuous Agent Optimization
May 8, 2026 · 5 min read
Today we're launching Learning Agents in public preview on our cloud. Learning agents continuously optimize the prompt, tools, model selection, and reasoning flow of deployed agents, driven entirely by production traffic, with no human in the optimization loop. You review the resulting versions and decide what ships.
The Problem: Agent Drift and Manual Optimization
Agent applications face a unique challenge compared to traditional software. Their behavior is probabilistic, their failure modes are subtle, and their optimization surface is vast. You can tune prompts, tools, model selection, reasoning effort, architecture, and more. A small prompt change can fix one failure pattern while introducing another.
When something breaks, debugging is mostly forensic. Teams pull traces from production logs, look for similar inputs that already work, tweak the prompt or swap the model, then rerun their evaluations to see whether the fix holds without regressing other cases.
Most teams optimize through a manual loop: deploy, wait for bugs, investigate, hypothesize, test locally, deploy again, hope. It's slow, reactive, and doesn't scale.
Learning Agents: Continuous Agent Optimization
Learning agents are a system for data-driven, fully automated agent optimization. You define the objectives (for example, "maximize accuracy, then minimize cost"), and Motus runs the optimization. It dynamically constructs evaluation datasets from your production traffic, proposes changes to the agent's harness (the system prompt, tool configuration, model selection, and reasoning loop that surround the model), evaluates each candidate, and converges on a set of versions on the pareto frontier.
There's rarely a single "best" version of an agent. A version that maximizes accuracy might cost 3x more than one that's nearly as good; a fast, cheap version might fail on complex edge cases. Learning agents produce a menu of pareto-optimal versions across quality and cost, and the developer chooses which one to deploy based on their priorities.
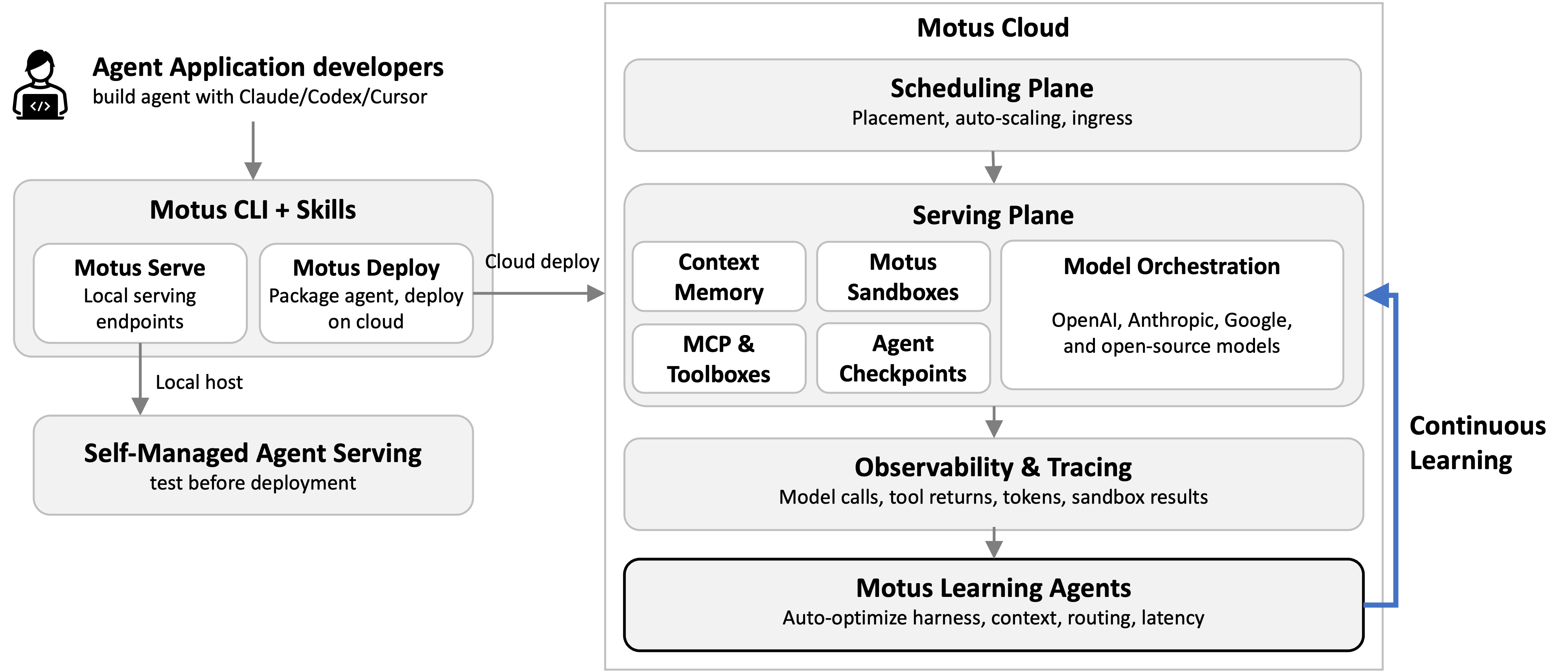
Inside Motus Cloud
Learning agents are part of Motus Cloud, our platform for deploying and operating production agents. The motus Python library works with agents built using the OpenAI Agents SDK, Anthropic SDK, Google ADK, or plain Python, with no rewrite required. motus deploy ships your agent to the cloud; motus serve runs it on your own infrastructure.
Behind that single command, Motus handles scheduling and model orchestration across OpenAI, Anthropic, Google, and open-source models. It also provides context memory, sandboxed execution, and full observability, and feeds those traces directly into learning agents.
Datasets from Production Traffic
The core idea behind learning agents: every optimization decision should be validated against a representative dataset. Datasets aren't just for one-time benchmarking. They're the continuous feedback signal that drives improvement.
Motus constructs datasets from production traffic in several ways depending on the use case:
- Regression sets built from previously passing cases, catching regressions whenever the agent changes
- Error-driven sets assembled from failing or flagged requests, focusing the optimizer on real problems
- Traffic-sampled sets drawn from the live request distribution, optimizing for what users actually need
- Cost-focused sets targeting the most expensive requests, finding where cost savings have the most impact
For example, an error-driven set might pull every failing request from the past week, while a regression set pins every previously-passing case. Each candidate harness change has to clear both: improve on the optimization target, without breaking what already works. The principle: dataset construction is a platform concern; optimization is the learning agents' job.
Safety: What If It Makes Things Worse?
Autonomous optimization raises an obvious question: what happens when a candidate version is worse than what's currently deployed? Learning agents are designed around the assumption that most iterations will fail, with most candidates pruned before they reach the pareto front.
Every candidate version is evaluated against the full regression set before it can advance. A version that improves on the target metric but regresses on previously passing cases is discarded. Advancement requires strict improvement: better on the optimization objective, no worse on everything else.
Developers retain full control over the deployment boundary. Learning agents produce a pareto front of candidate versions, but no version is deployed without explicit approval, either through manual selection in the console or through developer-configured auto-deploy rules with user-defined thresholds. The system optimizes; the developer decides what ships.
Walkthrough: Optimizing a Coding Agent
To show how learning agents work in practice, we ran a pilot on a small subset of SWE-bench Verified, a curated benchmark of real GitHub issues from open-source Python repositories. Each task hands the agent a bug report and the project's source tree, and the agent has to locate the relevant code, write a patch, and pass the project's existing test suite. The pilot below is an illustrative walkthrough of the optimization loop.
The baseline agent was deliberately minimal: Claude Opus 4.7 with a single bash tool, a short system prompt instructing it to read the repo, write a patch, and run tests, and no multi-step planning or verification. On a 20-task random sample from SWE-bench Verified, this baseline resolved 16 of 20 tasks. We set the learning agents to "maximize accuracy, then minimize cost."
Over 9 iterations, learning agents autonomously proposed changes to the agent's prompt structure, tool usage, and reasoning flow. Five of the nine candidates were dominated by an existing version and pruned; the remaining four landed on the pareto front. The chart below plots all 10 candidates in the (accuracy, cost) plane. The highlighted points in the bottom-right are the versions the developer ultimately receives, each best at some quality/cost tradeoff.
Version evolution on SWE-bench Verified (20 tasks) — bottom-right is better
A human defined the objective and selected the evaluation dataset; learning agents executed the entire optimization (proposing changes, running evaluations, and pruning dead ends) automatically. Full benchmark results on the complete SWE-bench Verified set are forthcoming.
Get Started
Learning agents are live in public preview on our cloud. Deploy your agent with motus deploy, and continuous optimization starts as soon as your agent sees traffic. No configuration, no separate eval pipeline, no manual prompt tuning. The tokens are on us during public preview.
We're working on several extensions next: cross-application learning (improvements discovered for one agent app may transfer to others), dataset evolution (as the agent improves, the dataset should get harder), and cost-aware search (incorporating eval cost into the search strategy itself).